Concepts of Database Management Henry Books Case Solutions
- 5.6.1 The database data model
- 5.6.2 Database notation
- 5.6.3 Database design
- 5.6.3.1 Entities and attributes
- 5.6.3.2 Relationships
- 5.6.3.3 Designing for data integrity
- 5.6.3.4 Database normalization
- 5.6.3.5 Denormalization
- 5.6.4 Flashback: The DRY principle
- 5.6.5 Case study: The Data Expo (continued)
- 5.6.6 Advantages and disadvantages
- 5.6.7 Flashback: Database design and XML design
- 5.6.8 Case study: The Data Expo (continued)
- 5.6.9 Database software
- Recap
5.6 Databases
When a data set becomes very large, or even just very complex in its structure, the ultimate storage solution is a database.
The term "database" can be used generally to describe any collection of information. In this section, the term "database" means a relational database, which is a collection of data that is organized in a particular way.
The actual physical storage mechanism for a database--whether binary formats or text formats are used, and whether one file or many files are used--will not concern us. We will only be concerned with the high-level, conceptual organization of the data and will rely on software to decide how best to store the information in files.
The software that handles the representation of the data in computer memory, and allows us to work at a conceptual level, is called a database management system (DBMS), or in our case, more specifically, a relational database management system (RDBMS).
The main benefits of databases for data storage derive from the fact that databases have a formal structure. We will spend much of this section describing and discussing how databases are designed, so that we can appreciate the benefits of storing data in a database and so that we know enough to be able to work with data that have been stored in a database.
5.6.1 The database data model
We are not concerned with the file formats that are used to store a database. Instead, we will deal with the conceptual components used to store data in a database.
A relational database consists of a set of tables, where a table is conceptually just like a plain text file or a spreadsheet: a set of values arranged in rows and columns. The difference is that there are usually several tables in a single database, and the tables in a database have a much more formal structure than a plain text file or a spreadsheet.
In order to demonstrate the concepts and terminology of databases, we will work with a simple example of storing information about books. The entire set of information is shown in Figure 5.18, but we will only consider specific subsets of book information at various stages throughout this section in order to demonstrate different ideas about databases.
ISBN title author gender publisher ctry ---------- ------------------------------------ ---------------- ------ ---------------- ---- 0618260307 The Hobbit J. R. R. Tolkien male Houghton Mifflin USA 0908606664 Slinky Malinki Lynley Dodd female Mallinson Rendel NZ 1908606206 Hairy Maclary from Donaldson's Dairy Lynley Dodd female Mallinson Rendel NZ 0393310728 How to Lie with Statistics Darrell Huff male W. W. Norton USA 0908783116 Mechanical Harry Bob Kerr male Mallinson Rendel NZ 0908606273 My Cat Likes to Hide in Boxes Lynley Dodd female Mallinson Rendel NZ 0908606273 My Cat Likes to Hide in Boxes Eve Sutton female Mallinson Rendel NZ |
Shown below is a simple example of a database table that contains information about some of the books in our data set. This table has three columns--the ISBN of the book, the title of the book, and the author of the book--and four rows, with each row representing one book.
ISBN title author ---------- -------------------------- ---------------- 0618260307 The Hobbit J. R. R. Tolkien 0908606664 Slinky Malinki Lynley Dodd 0393310728 How to Lie with Statistics Darrell Huff 0908783116 Mechanical Harry Bob Kerr
Each table in a database has a unique name and each column within a table has a unique name within that table.
Each column in a database table also has a data type associated with it, so all values in a single column are the same sort of data. In the book database example, all values in all three columns are text or character values. The ISBN is stored as text, not as an integer, because it is a sequence of 10 digits (as opposed to a decimal value). For example, if we stored the ISBN as an integer, we would lose the leading 0.
Each table in a database has a primary key. The primary key must be unique for every row in a table. In the book table, the ISBN provides a perfect primary key because every book has a different ISBN.
It is possible to create a primary key by combining the values of two or more columns. This is called a composite primary key. A table can only have one primary key, but the primary key may be composed from more than one column. We will see some examples of composite primary keys later in this chapter.
A database containing information on books might also contain information on book publishers. Below we show another table in the same database containing information on publishers.
ID name country -- ---------------- ------- 1 Mallinson Rendel NZ 2 W. W. Norton USA 3 Houghton Mifflin USA
In this table, the values in the ID column are all integers. The other columns all contain text. The primary key in this table is the ID column.
Tables within the same database can be related to each other using foreign keys. These are columns in one table that specify a value from the primary key in another table. For example, we can relate each book in the book_table to a publisher in the publisher_table by adding a foreign key to the book_table. This foreign key consists of a column, pub, containing the appropriate publisher ID. The book_table now looks like this:
ISBN title author pub ---------- -------------------------- ---------------- --- 0618260307 The Hobbit J. R. R. Tolkien 3 0908606664 Slinky Malinki Lynley Dodd 1 0393310728 How to Lie with Statistics Darrell Huff 2 0908783116 Mechanical Harry Bob Kerr 1
Notice that two of the books in the book_table have the same publisher, with a pub value of 1. This corresponds to the publisher with an ID value of 1 in the publisher_table, which is the publisher called Mallinson Rendel.
Also notice that a foreign key column in one table does not have to have the same name as the primary key column that it refers to in another table. The foreign key column in the book_table is called pub, but it refers to the primary key column in the publisher_table called ID.
5.6.2 Database notation
The examples of database tables in the previous section have shown the contents of each database table. In the next section, on Database Design, it will be more important to describe the design, or structure, of a database table--the table schema. For this purpose, the contents of each row are not important; instead, we are most interested in how many tables there are and which columns are used to make up those tables.
We can describe a database design simply in terms of the names of tables, the names of columns, which columns are primary keys, and which columns are foreign keys.
The notation that we will use is a simple text description, with primary keys and foreign keys indicated in square brackets. The description of a foreign key includes the name of the table and the name of the column that the foreign key refers to. For example, these are the schema for the publisher_table and the book_table in the book database:
publisher_table ( ID [PK], name, country ) book_table ( ISBN [PK], title, author, pub [FK publisher_table.ID] )
The diagram below shows one way that this design could be visualized. Each "box" in this diagram represents one table in the database, with the name of the table as the heading in the box. The other names in each box are the names of the columns within the table; if the name is bold , then that column is part of the primary key for the table and if the name is italic , then that column is a foreign key. Arrows are used to show the link between a foreign key in one table and the primary key in another table.

The publisher_table has three columns and the column named ID is the primary key for the table.
The book_table has four columns. In this table, the primary key is the ISBN column and the pub column is a foreign key that refers to the ID column in the publisher_table.
5.6.3 Database design
Like we saw with XML documents in Section 5.5.2, databases allow us to store information in a variety of ways, which means that there are design decisions to be made. In this section, we will briefly discuss some of the issues relating to database design.
The design of a database comes down to three things: how many tables are required; what information goes in each table; and how the tables are linked to each other. The remainder of this section provides some rules and guidelines for determining a solution for each of these steps.
This section provides neither an exhaustive discussion nor a completely rigorous discussion of database design. The importance of this section is to provide a basic introduction to some useful ideas and ways to think about data. A basic understanding of these issues is also necessary for us to be able to work with data that have been stored in a database.
5.6.3.1 Entities and attributes
One way to approach database design is to think in terms of entities, their attributes, and the relationships between them.
An entity is most easily thought of as a person, place, or physical object (e.g., a book); an event; or a concept. An attribute is a piece of information about the entity. For example, the title, author, and ISBN are all attributes of a book entity.
In terms of a research data set, each variable in the data set corresponds to an attribute. The task of designing a database to store the data set comes down to assigning each variable to a particular entity.
Having decided upon a set of entities and their attributes, a database design consists of a separate table for each entity and a separate column within each table for each attribute of the corresponding entity.
Rather than storing a data set as one big table of information, this rule suggests that we should use several tables, with information about different entities in separate tables. In the book database example, there is information about at least two entities, books and publishers, so we have a separate table for each of these.
These ideas of entities and attributes are the same ideas that were discussed for XML design back in Section 5.5.2, just with different terminology.
5.6.3.2 Relationships
A relationship is an association between entities. For example, a publisher publishes books and a book is published by a publisher. Relationships are represented in a database by foreign key-primary key pairs, but the details depend on the cardinality of the relationship--whether the relationship is one-to-one, many-to-one, or many-to-many.
For example, a book is published by exactly one publisher, but a publisher publishes many books, so the relationship between books and publishers is many-to-one.
This sort of relationship can be represented by placing a foreign key in the table for books (the "many" side) that refers to the primary key in the table for publishers (the "one" side). This is the design that we have already seen, on page ![]() , where the book_table has a foreign key, pub, that refers to the primary key, ID, in the publisher_table.
, where the book_table has a foreign key, pub, that refers to the primary key, ID, in the publisher_table.
One-to-one relationships can be handled similarly to many-to-one relationships (it does not matter which table gets the foreign key), but many-to-many relationships are more complex.
In our book database example, we can identify another sort of entity: authors.
In order to accommodate information about authors in the database, there should be another table for author information. In the example below, the table only contains the author's name, but other information, such as the author's age and nationality, could be added.
author_table ( ID [PK], name )
What is the relationship between books and authors? An author can write several books and a book can have more than one author, so this is an example of a many-to-many relationship.
A many-to-many relationship can only be represented by creating a new table in the database.
For example, we can create a table, called the book_author_table, that contains the relationship between authors and books. This table contains a foreign key that refers to the author table and a foreign key that refers to the book table. The representation of book entities, author entities, and the relationship between them now consists of three tables, as shown below.
author_table ( ID [PK], name ) book_table ( ISBN [PK], title, pub [FK publisher_table.ID] ) book_author_table ( ID [PK], book [FK book_table.ISBN], author [FK author_table.ID] )
The book database design, with author information included, is shown in the diagram below.
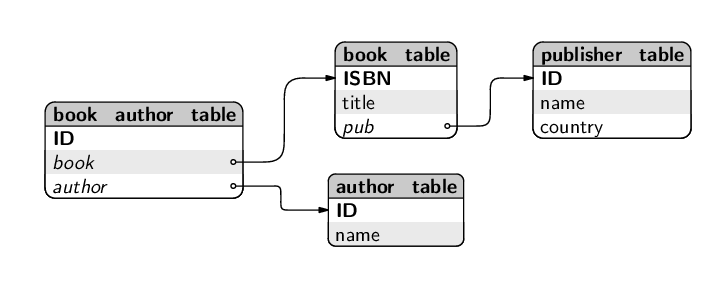
The contents of these tables for several books are shown below. The author table just lists the authors for whom we have information:
ID name -- ----------- 2 Lynley Dodd 5 Eve Sutton
The book_table just lists the books that are in the database:
ISBN title pub ---------- ------------------------------------ --- 0908606664 Slinky Malinki 1 1908606206 Hairy Maclary from Donaldson's Dairy 1 0908606273 My Cat Likes to Hide in Boxes 1
The book_author_table contains the association between books and authors:
ID book author -- ---------- ------ 2 0908606664 2 3 1908606206 2 6 0908606273 2 7 0908606273 5
Notice that author 2 (Lynley Dodd) has written more than one book and book 0908606273 (My Cat Likes to Hide in Boxes) has more than one author.
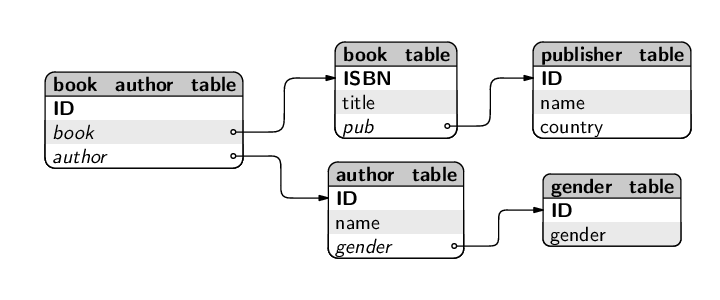
5.6.3.3 Designing for data integrity
Another reason for creating a table in a database is for the purpose of constraining the set of possible values for an attribute. For example, if the table of authors records the gender of the author, it can be useful to have a separate table that contains the possible values of gender. The column in the author table then becomes a foreign key referring to the gender table and, because a foreign key must match the value of the corresponding primary key, we have a check on the validity of the gender values in the author table.
The redesigned author table and gender table are described below.
author_table ( ID [PK], name, gender [FK gender_table.ID] ) gender_table ( ID [PK], gender )
The gender_table only contains the set of possible gender values, as shown below.
ID gender -- ------ 1 male 2 female
The final book database design, consisting of five tables, is shown in the diagram below.
5.6.3.4 Database normalization
Another way to approach database design is to choose tables and columns within tables based on whether they satisfy a set of rules called normal forms.
This, more formal, process of database design is called normalization.
There are several normal forms, but we will only mention the first three because these will cover most simple situations.
The proper definition of normalization depends on more advanced relational database concepts that are beyond the scope of this book, so the descriptions below are just to give a feel for how the process works.
- First normal form
-
First normal form requires that the columns in a table must be atomic, there should be no duplicative columns, and every table must have a primary key.The first part of this rule says that a column in a database table must only contain a single value. As an example, consider the following possible design for a table for storing information about books. There is one column for the title of the book and another column for all authors of the book.
book_table ( title, authors )
Two rows of this table are shown below.
title authors ----------------------------- ----------------------- Slinky Malinki Lynley Dodd My Cat Likes to Hide in Boxes Eve Sutton, Lynley Dodd
The first column of this table is acceptable because it just contains one piece of information: the title of the book. However, the second column is not atomic because it contains a list of authors for each book. The book on the second row has two authors recorded in the authors column. This violates first normal form.
The second part of the rule says that a table cannot have two columns containing the same information. For example, the following possible redesign of the book table provides a solution to the previous problem by having a separate column for each author of the book.
book_table ( title, author1, author2 )
Two rows from this table are shown below.
title author1 author2 ----------------------------- ----------- ----------- Slinky Malinki Lynley Dodd NULL My Cat Likes to Hide in Boxes Eve Sutton Lynley Dodd
This solves the problem of atomic columns because each column only contains the name of one author. However, the table has two duplicative columns: author1 and author2. These two columns both record the same information, author names, so this design also violates first normal form.
A possible redesign that satisfies the requirement that each column is atomic and not duplicative is shown below. We now have just one column for the book title and one column for the names of the authors.
book_table ( title, author )
The contents of this table are shown below. Notice that the second book now occupies two rows because it has two authors.
title author ----------------------------- ----------- Slinky Malinki Lynley Dodd My Cat Likes to Hide in Boxes Eve Sutton My Cat Likes to Hide in Boxes Lynley Dodd
The final part of the first normal form rule says that there must be a column in the table that has a unique value in every row (or it must be possible to combine several columns to obtain a unique value for every row). In other words, every table must have a primary key.
Can we find a primary key in the table above?
Neither the title column nor the author column by itself is any use as a primary key because some values repeat in each of these columns.
We could combine the two columns to create a composite primary key. However, it is also important to think about not just the data that are currently in a table, but also what possible values could be entered into the table in the future (or even just in theory). In this case, it is possible that a book could be published in both hard cover and paperback formats, both of which would have the same title and author, so while a composite primary key would work for the three rows shown below, it is not necessarily a smart choice.
As described previously, for the case of information about books, a great candidate for a primary key is the book's ISBN because it is guaranteed to be unique for a particular book. If we add an ISBN column to the table, we can finally satisfy first normal form, though it still has to be a composite primary key involving the combination of ISBN and author.
book_table ( ISBN [PK], title, author [PK] )
The contents of this table are shown below.
ISBN title author ---------- ----------------------------- ----------- 0908606664 Slinky Malinki Lynley Dodd 0908606273 My Cat Likes to Hide in Boxes Lynley Dodd 0908606273 My Cat Likes to Hide in Boxes Eve Sutton
This is not an ideal solution for storing this information, but at least it satisfies first normal form. Consideration of second and third normal form will help to improve the design.
- Second normal form
-
Second normal form requires that a table must be in first normal form and all columns in the table must relate to the entire primary key.This rule formalizes the idea that there should be a table for each entity in the data set.
As a very basic example, consider the following table that contains information about authors and publishers. The primary key of this table is the author ID. In other words, each row of this table only concerns a single author.
author_table ( ID [PK], name, publisher)
Two rows from this table are shown below.
ID name publisher -- ----------- ---------------- 2 Lynley Dodd Mallinson Rendel 5 Eve Sutton Mallinson Rendel
The name column of this table relates to the primary key (the ID); this is the name of the author. However, the publisher column does not relate to the primary key. This is the publisher of a book. In other words, the information about publishers belongs in a table about publishers (or possibly a table about books), not in a table about authors.
As a more subtle example, consider the table that we ended up with at the end of first normal form.
book_table ( ISBN [PK], title, author [PK] )
ISBN title author ---------- ----------------------------- ----------- 0908606664 Slinky Malinki Lynley Dodd 0908606273 My Cat Likes to Hide in Boxes Lynley Dodd 0908606273 My Cat Likes to Hide in Boxes Eve Sutton
The primary key for this table is a combination of ISBN and author (each row of the table carries information about one author of one book).
The title column relates to the ISBN; this is the title of the book. However, the title column does not relate to the author; this is not the title of the author!
The table needs to be split into two tables, one with the information about books and one with the information about authors. Shown below is the book-related information separated into its own table.
book_table ( ISBN [PK], title )
ISBN title ---------- ----------------------------- 0908606273 My Cat Likes to Hide in Boxes 0908606664 Slinky Malinki
It is important to remember that each of the new tables that we create to satisfy second normal form must also satisfy first normal form. In this case, it would be wise to add an ID column to act as the primary key for the table of authors, as shown below, because it is entirely possible that two distinct authors could share the same name.
author_table ( ID [PK], author )
ID author -- ----------- 2 Lynley Dodd 5 Eve Sutton
As this example makes clear, having split a table into two or more pieces, it is very important to link the pieces together by adding one or more foreign keys, based on the relationships between the tables. In this case, the relationship is many-to-many, so the solution requires a third table to provide a link between books and authors.
book_author_table ( ID [PK], book [FK book_table.ISBN], author [FK author_table.ID] )
ID book author -- ---------- ------ 2 0908606664 2 6 0908606273 2 7 0908606273 5
- Third normal form
-
Third normal form requires that a table must be in second normal form and all columns in the table must relate only to the primary key (not to each other).This rule further emphasizes the idea that there should be a separate table for each entity in the data set. For example, consider the following table for storing information about books.
book_table ( ISBN [PK], title, publisher, country )
ISBN title publisher country ---------- ---------------- ---------------- ------- 0395193958 The Hobbit Houghton Mifflin USA 0836827848 Slinky Malinki Mallinson Rendel NZ 0908783116 Mechanical Harry Mallinson Rendel NZ
The primary key of this table is the ISBN, which uniquely identifies a book. The title column relates to the book; this is the title of the book. Each row of this table is about one book.
The publisher column also relates to the book; this is the publisher of the book. However, the country column does not relate directly to the book; this is the country of the publisher. That obviously is information about the book--it is the country of the publisher of the book--but the relationship is indirect, through the publisher.
There is a simple heuristic that makes it easy to spot this sort of problem in a database table. Notice that the information in the publisher and country columns is identical for the books published by Mallinson Rendel. When two or more columns repeat the same information over and over, it is a sure sign that either second or third normal form is not being met.
In this case, the analysis of the table suggests that there should be a separate table for information about the publisher.
Applying the rules of normalization usually results in the creation of multiple tables in a database. The previous discussion of relationships should be consulted for making sure that any new tables are linked to at least one other table in the database using a foreign-key, primary-key pair.
5.6.3.5 Denormalization
The result of normalization is a well-organized database that should be easy to maintain. However, normalization may produce a database that is slow in terms of accessing the data (because the data from many tables has to be recombined).
Denormalization is the process of deliberately violating normal forms, typically in order to produce a database that can be accessed more rapidly.
5.6.4 Flashback: The DRY principle
A well-designed database, particularly one that satisfies third normal form, will have the feature that each piece of information is stored only once. Less repetition of data values means that a well-designed database will usually require less memory than storing an entire data set in a naïve single-table format. Less repetition also means that a well-designed database is easier to maintain and update, because if a change needs to be made, it only needs to be made in one location. Furthermore, there is less chance of errors creeping into the data set. If there are multiple copies of information, then it is possible for the copies to disagree, but with only one copy there can be no disagreements.
These ideas are an expression of the DRY principle from Section 2.7. A well-designed database is the ultimate embodiment of the DRY principle for data storage.
5.6.5 Case study: The Data Expo (continued)
The Data Expo data set consists of seven atmospheric variables recorded at 576 locations for 72 time points (every month for 6 years), plus elevation data for each location (see Section 5.2.8).
The data were originally stored as 505 plain text files, where each file contains the data for one variable for one month. Figure 5.19 shows the first few lines from one of the plain text files.
As we have discussed earlier in this chapter, this simple format makes the data very accessible. However, this is an example where a plain text format is quite inefficient, because many values are repeated. For example, the longitude and latitude information for each location in the data set is stored in every single file, which means that that information is repeated over 500 times! That not only takes up more storage space than is necessary, but it also violates the DRY principle, with all of the negative consequences that follow from that.
VARIABLE : Mean TS from clear sky composite (kelvin) FILENAME : ISCCPMonthly_avg.nc FILEPATH : /usr/local/fer_dsets/data/ SUBSET : 24 by 24 points (LONGITUDE-LATITUDE) TIME : 16-JAN-1995 00:00 113.8W 111.2W 108.8W 106.2W 103.8W 101.2W 98.8W ... 27 28 29 30 31 32 33 ... 36.2N / 51: 272.7 270.9 270.9 269.7 273.2 275.6 277.3 ... 33.8N / 50: 279.5 279.5 275.0 275.6 277.3 279.5 281.6 ... 31.2N / 49: 284.7 284.7 281.6 281.6 280.5 282.2 284.7 ... 28.8N / 48: 289.3 286.8 286.8 283.7 284.2 286.8 287.8 ... 26.2N / 47: 292.2 293.2 287.8 287.8 285.8 288.8 291.7 ... 23.8N / 46: 294.1 295.0 296.5 286.8 286.8 285.2 289.8 ... ... |
In this section, we will consider how the Data Expo data set could be stored as a relational database.
To start with, we will consider the problem from an entities and attributes perspective. What entities are there in the data set? In this case, the different entities that are being measured are relatively easy to identify. There are measurements on the atmosphere, and the measurements are taken at different locations and at different times. We have information about each time point (i.e., a date), we have information about each location (longitude and latitude and elevation), and we have several measurements on the atmosphere. This suggests that we should have three tables: one for atmospheric measures, one for locations, and one for time points.
It is also useful to look at the data set from a normalization perspective. For this purpose, we will start with all of the information in a single table (only 7 rows shown):
date lon lat elv chi cmid clo ozone press stemp temp ---------- ------ ----- --- ---- ---- ---- ----- ------ ----- ----- 1995-01-16 -56.25 36.25 0.0 25.5 17.5 38.5 298.0 1000.0 289.8 288.8 1995-01-16 -56.25 33.75 0.0 23.5 17.5 36.5 290.0 1000.0 290.7 289.8 1995-01-16 -56.25 31.25 0.0 20.5 17.0 36.5 286.0 1000.0 291.7 290.7 1995-01-16 -56.25 28.75 0.0 12.5 17.5 37.5 280.0 1000.0 293.6 292.2 1995-01-16 -56.25 26.25 0.0 10.0 14.0 35.0 272.0 1000.0 296.0 294.1 1995-01-16 -56.25 23.75 0.0 12.5 11.0 32.0 270.0 1000.0 297.4 295.0 1995-01-16 -56.25 21.25 0.0 7.0 10.0 31.0 260.0 1000.0 297.8 296.5
In terms of first normal form, all columns are atomic and there are no duplicative columns, and we can, with a little effort, find a (composite) primary key: we need a combination of date, lon (longitude), and lat (latitude) to get a unique value for all rows.
Moving on to second normal form, the column elv (elevation) immediately fails. The elevation at a particular location clearly relates to the longitude and latitude of the location, but it has very little to do with the date. We need a new table to hold the longitude, latitude, and elevation data.
The new table design and the first three rows of data are shown below.
location_table ( longitude [PK], latitude [PK], elevation )
lon lat elv ------ ----- --- -56.25 36.25 0.0 -56.25 33.75 0.0 -56.25 31.25 0.0
This "location" table is in third normal form. It has a primary key (a combination of longitude and latitude), and the elv column relates directly to the entire primary key.
Going back to the original table, the remaining columns of atmospheric measurements are all related to the primary key; the data in these columns represent an observation at a particular location at a particular time point.
However, we now have two tables rather than just one, so we must make sure that the tables are linked to each other, and in order to achieve this, we need to determine the relationships between the tables.
We have two tables, one representing atmospheric measurements, at various locations and times, and one representing information about the locations. What is the relationship between these tables? Each location (each row of the location table) corresponds to several measurements, but each individual measurement (each row of the measurement table) corresponds to only one location, so the relationship is many-to-one.
This means that the table of measurements should have a foreign key that references the primary key in the location table. The design could be expressed like this:
location_table ( longitude [PK], latitude [PK], elevation ) measure_table ( date [PK], longitude [PK] [FK location_table.longitude], latitude [PK] [FK location_table.latitude], cloudhigh, cloudlow, cloudmid, ozone, pressure, surftemp, temperature )
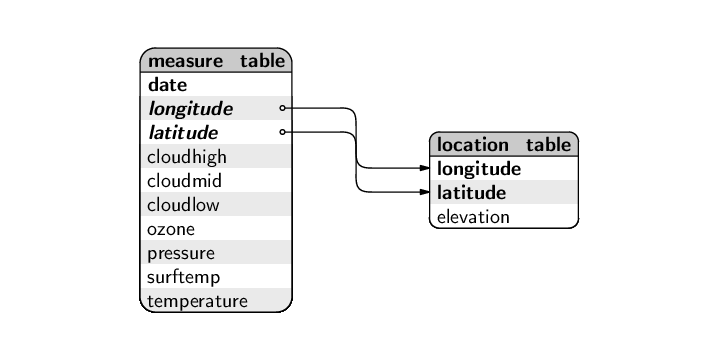
Both tables have composite primary keys. The measure_table also has a composite foreign key, to refer to the composite primary key in the location_table. Finally, the longitude and latitude columns have roles in both the primary key and the foreign key of the measure_table.
A possible adjustment to the database design is to consider a surrogate auto-increment key--a column that just corresponds to the row number in the table--as the primary key for the location table, because the natural primary key is quite large and cumbersome. This leads to a final design that can be expressed as below.
location_table ( ID [PK], longitude, latitude, elevation ) measure_table ( date [PK], location [PK] [FK location_table.ID], cloudhigh, cloudlow, cloudmid, ozone, pressure, surftemp, temperature )
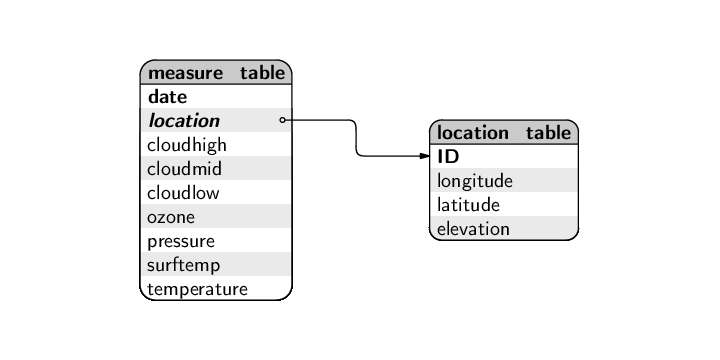
Another adjustment would be to break out the date column into a separate table. This is partly motivated by the idea of data integrity; a separate table for dates would ensure that all dates in the measure_table are valid dates. Also, if the table for dates uses an auto-increment ID column, the date column in the measure_table can become just a simple integer, rather than a lengthy date value. Finally, the table of date information can have the year and month information split into separate columns, which can make it more useful to work with the date information.
The final Data Expo database design is shown below.
date_table ( ID [PK], date, month, year ) location_table ( ID [PK], longitude, latitude, elevation ) measure_table ( date [PK] [FK date_table.ID], location [PK] [FK location_table.ID], cloudhigh, cloudlow, cloudmid, ozone, pressure, surftemp, temperature )
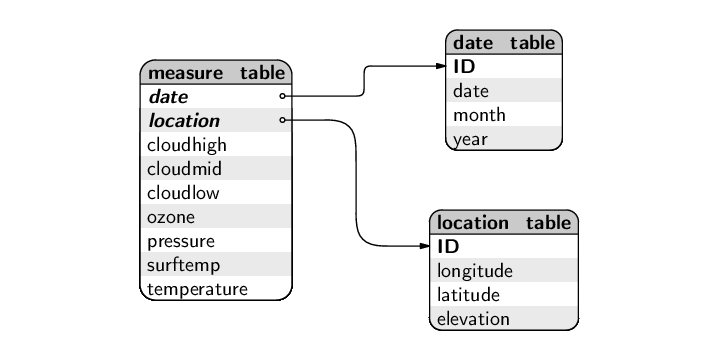
As a final check, we should confirm that these tables all satisfy third normal form.
Each table has a primary key, all columns are atomic, and there are no duplicative columns, so first normal form is satisfied. All of the columns in each table correspond to the primary key of the table--in particular, each measurement in the measure_table corresponds to a particular combination of date and location--so second normal form is also satisfied. The tables mostly also satisfy third normal form because columns generally relate only to the primary key in the table. However, it could be argued that, in the date_table, the month and year columns relate to the date column as well as to the primary key of the table. This is a good demonstration of a possible justification for denormalization; we have split out these columns because we anticipate that they will be useful for asking questions of the database in the future. The ideas of normalization should be used as guides for achieving a sensible database design, but other considerations may also come into play.
5.6.6 Advantages and disadvantages
The previous sections have demonstrated that databases are a lot more complex than most of the other data storage options in this chapter. In this section, we will look at what we can gain by using a database to store a data set and what the costs are compared to other storage formats.
The relatively formal data model of relational databases, and the relatively complex processes that go into designing an appropriate database structure, are worthwhile because the resulting structure enforces constraints on the data in a database, which means that there are checks on the accuracy and consistency of data that are stored in a database. In other words, databases ensure better data integrity.
For example, the database structure ensures that all values in a single column of a table are of the same data type (e.g., they are all numbers). It is possible, when setting up a database, to enforce quite specific constraints on what values can appear in a particular column of a table. Section 8.3 provides some information on this topic of the creation of data sets.
Another important structural feature of databases is the existence of foreign keys and primary keys. Database software will enforce the rule that a primary key must be unique for every row in a table, and it will enforce the rule that the value of a foreign key must refer to an existing primary key value.
Databases tend to be used for large data sets because, for most DBMS, there is no limit on the size of a database. However, even when a data set is not enormous, there are advantages to using a database because the organization of the data can improve accuracy and efficiency. In particular, databases allow the data to be organized in a variety of ways so that, for example, data with a hierarchical structure can be stored in an efficient and natural way.
Databases are also advantageous because most DBMS provide advanced features that are far beyond what is provided by the software that is used to work with data in other formats (e.g., text editors and spreadsheet programs). These features include the ability to allow multiple people to access and even modify the data at once and advanced security to control who has access to the data and who is able to modify the data.
The first cost to consider is monetary. The commercial database systems offered by Oracle and Microsoft can be very expensive, although open source options exist (see Section 5.6.9) to relieve that particular burden. However, there is also the cost of acquiring or hiring the expertise necessary to create, maintain, and interact with data stored in a database.
Another disadvantage of using a database as a storage format is that the data can only be accessed using a specific piece of DBMS software.
Finally, all of the sophistication and flexibility that a database provides may just not be necessary for small data sets or for data sets that have a simple structure. For example, a binary format such as netCDF is very well suited to a geographical data set where observations are made on a regular grid of locations and at a fixed set of time points and it will outperform a more general-purpose database solution.
The investment required to create and maintain a database means that it will not always be an appropriate choice.
5.6.7 Flashback: Database design and XML design
In Section 5.5.2 we discussed some basic ideas for deciding how to represent a data set in an XML format.
The ideas of database design that we have discussed in Section 5.6.3--entities, attributes, relationships, and normalization--are very similar to the ideas from XML design, if a little more formal.
This similarity arises from the fact that we are trying to solve essentially the same problem in both cases, and this can be reflected in a simple correspondence between database designs and XML designs for the same data set.
As a rough guideline, a database table can correspond to a set of XML elements of the same type. Each row of the table will correspond to a single XML element, with each column of values recorded as a separate attribute within the element. The caveats about when attributes cannot be used still apply (see page ![]() ).
).
Simple one-to-one or many-to-one relationships can be represented in XML by nesting several elements (the many) within another element (the one). More complex relationships cannot be solved by nesting, but attributes corresponding to primary keys and foreign keys can be used to emulate relationships between entities via XML elements that are not nested.
5.6.8 Case study: The Data Expo (continued)
The Data Expo data set consists of several atmospheric measurements taken at many different locations and at several time points. A database design that we developed for storing these data consisted of three tables: one for the location data, one for the time data, and one for the atmospheric measurements (see Section 5.6.5). The database schema is reproduced below for easy reference.
date_table ( ID [PK], date, month, year ) location_table ( ID [PK], longitude, latitude, elevation ) measure_table ( date [PK] [FK date_table.ID], location [PK] [FK location_table.ID], cloudhigh, cloudlow, cloudmid, ozone, pressure, surftemp, temperature )
We can translate this database design into an XML document design very simply, by creating a set of elements for each table, with attributes for each column of data. For example, the fact that there is a table for location information implies that we should have location elements, with an attribute for each column in the database table. The data for the first few locations are represented like this in a database table:
ID lon lat elv ------ ----- --- ---------- 1 -113. 36. 1526.25 2 -111. 36. 1759.56 3 -108. 36. 1948.38
The same data could be represented in XML like this:
<location id="1" longitude="-113.75" latitude="36.25" elevation="1526.25" /> <location id="2" longitude="-111.25" latitude="36.25" elevation="1759.56" /> <location id="3" longitude="-108.75" latitude="36.25" elevation="1948.38" />
As an analogue of the primary keys in the database design, the DTD for this XML design could specify id as an ID attribute (see Section 6.2.2).
An XML element for the first row from the date_table might look like this (again with id as an ID attribute in the DTD):
<date id="1" date="1995-01-16" month="January" year="1995" />
Because there is a many-to-many relationship between locations and dates, it would not make sense to nest the corresponding XML elements. Instead, the XML elements that correspond to the rows of the measure_table could include attributes that refer to the relevant location and date elements. The following code shows an example of what a measure XML element might look like.
<measure date="1" location="1" cloudhigh="26.0" cloudmid="34.5" cloudlow="7.5" ozone="304.0" pressure="835.0" surftemp="272.7" temperature="272.1" />
In order to enforce the data integrity of the attributes date and location, the DTD for this XML design would specify these as IDREF attributes (see Section 6.2.2).
5.6.9 Database software
Every different database software product has its own format for storing the database tables on disk, which means that data stored in a database are only accessible via one specific piece of software.
This means that, if we are given data stored in a particular database format, we are forced to use the corresponding software. Something that slightly alleviates this problem is the existence of a standard language for querying databases. We will meet this language, SQL, in Chapter 7.
If we are in the position of storing information in a database ourselves, there are a number of fully featured open source database management systems to choose from. PostgreSQL 5.6 and MySQL 5.7 are very popular options, though they require some investment in resources and expertise to set up because they have separate client and server software components. SQLite 5.8 is much simpler to set up and use, especially for a database that only requires access by a single person working on a single computer.
Section 7.2.14 provides a very brief introduction to SQLite.
The major proprietary database systems include Oracle, Microsoft SQL Server, and Microsoft Access. The default user interface for these software products is based on menus and dialogs so they are beyond the scope and interest of this book. Nevertheless, in all of these, as with the default interfaces for the open source database software, it is possible to write computer code to access the data. Writing these data queries is the topic of the next chapter.
Recap
A database consists of one or more tables. Each column of a database table contains only one type of information, corresponding to one variable from a data set.A primary key uniquely identifies each row of a table. A primary key is a column in a table with a different value on every row.
A foreign key relates one table to another within a database. A foreign key is a column in a table that refers to the values in the primary key of another table.
A database should be designed so that information about different entities resides in separate tables.
Normalization is a way to produce a good database design.
Databases can handle large data sets and data sets with a complex structure, but databases require specific software and a certain level of expertise.
Paul Murrell

This work is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 New Zealand License.
Concepts of Database Management Henry Books Case Solutions
Source: https://www.stat.auckland.ac.nz/~paul/ItDT/HTML/node42.html